Series
Introduction to Hierarchical Data Format (HDF5) - Using HDFView and R
This series goes through what the HDF5 format is and how to open, read, and create HDF5 files in R. We also cover extracting and plotting data from HDF5 files.
Data used in this series are from the National Ecological Observatory Network (NEON) and are in HDF5 format.
Series Objectives
After completing the series you will:
- Understand how data can be structured and stored in HDF5
- Understand how metadata can be added to an HDF5 file
- Know how to explore HDF5 files using HDFView, a free tool for viewing HDF4 and HDF5 files
- Know how to work with HDF5 files in R
- Know how to work with time-series data within a nested HDF5 file
Things You’ll Need To Complete This Series
You will need the most current version of R and, preferably, RStudio loaded on your computer to complete this tutorial.
R is a programming language that specializes in statistical computing. It is a powerful tool for exploratory data analysis. To interact with R, we strongly recommend using RStudio, an interactive development environment (IDE).
Download Data
Data is available for download in those tutorials that focus on teaching data skills.
Hierarchical Data Formats - What is HDF5?
Last Updated: Apr 10, 2025
Learning Objectives
After completing this tutorial, you will be able to:
- Explain what the Hierarchical Data Format (HDF5) is.
- Describe the key benefits of the HDF5 format, particularly related to big data.
- Describe both the types of data that can be stored in HDF5 and how it can be stored/structured.
About Hierarchical Data Formats - HDF5
The Hierarchical Data Format version 5 (HDF5), is an open source file format that supports large, complex, heterogeneous data. HDF5 uses a "file directory" like structure that allows you to organize data within the file in many different structured ways, as you might do with files on your computer. The HDF5 format also allows for embedding of metadata making it self-describing.

Hierarchical Structure - A file directory within a file
The HDF5 format can be thought of as a file system contained and described
within one single file. Think about the files and folders stored on your computer.
You might have a data directory with some temperature data for multiple field
sites. These temperature data are collected every minute and summarized on an
hourly, daily and weekly basis. Within one HDF5 file, you can store a similar
set of data organized in the same way that you might organize files and folders
on your computer. However in a HDF5 file, what we call "directories" or "folders"
on our computers, are called groups and what we call files on our
computer are called datasets.
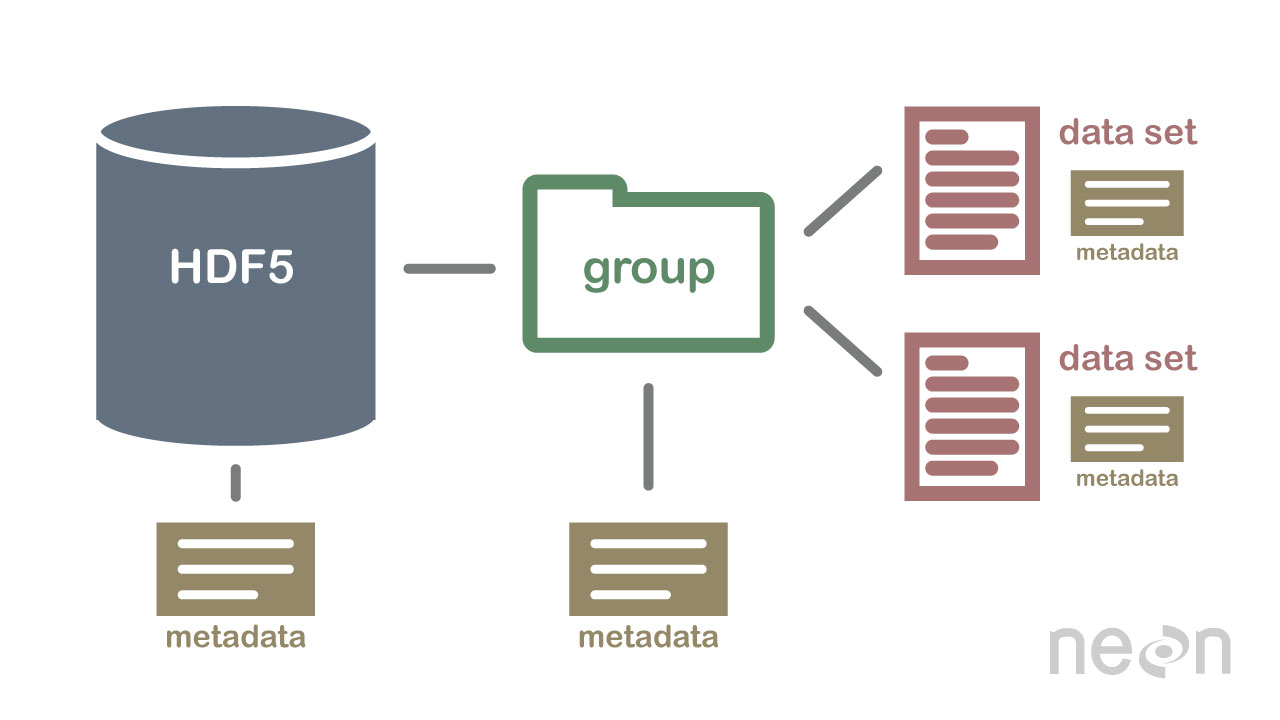
2 Important HDF5 Terms
- Group: A folder like element within an HDF5 file that might contain other groups OR datasets within it.
- Dataset: The actual data contained within the HDF5 file. Datasets are often (but don't have to be) stored within groups in the file.
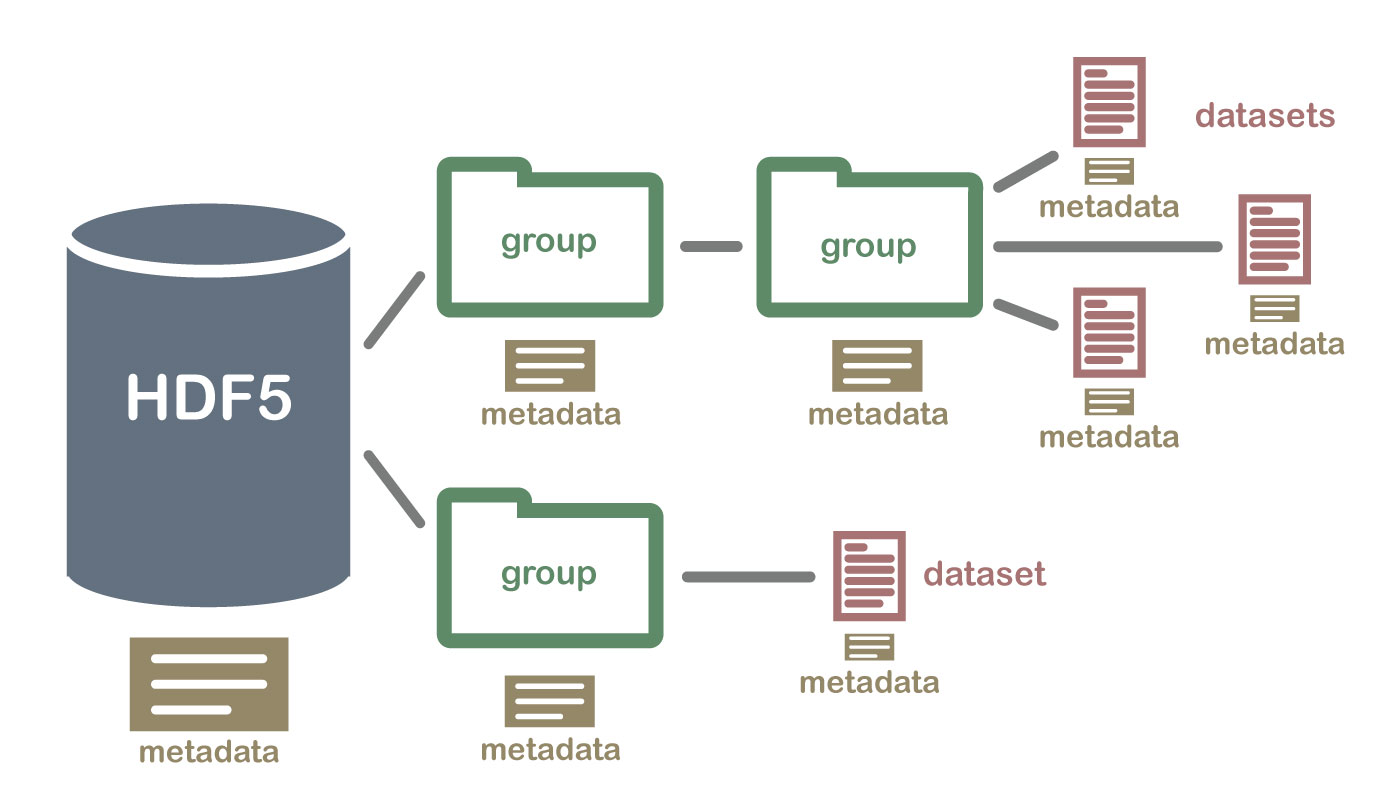
An HDF5 file containing datasets, might be structured like this:
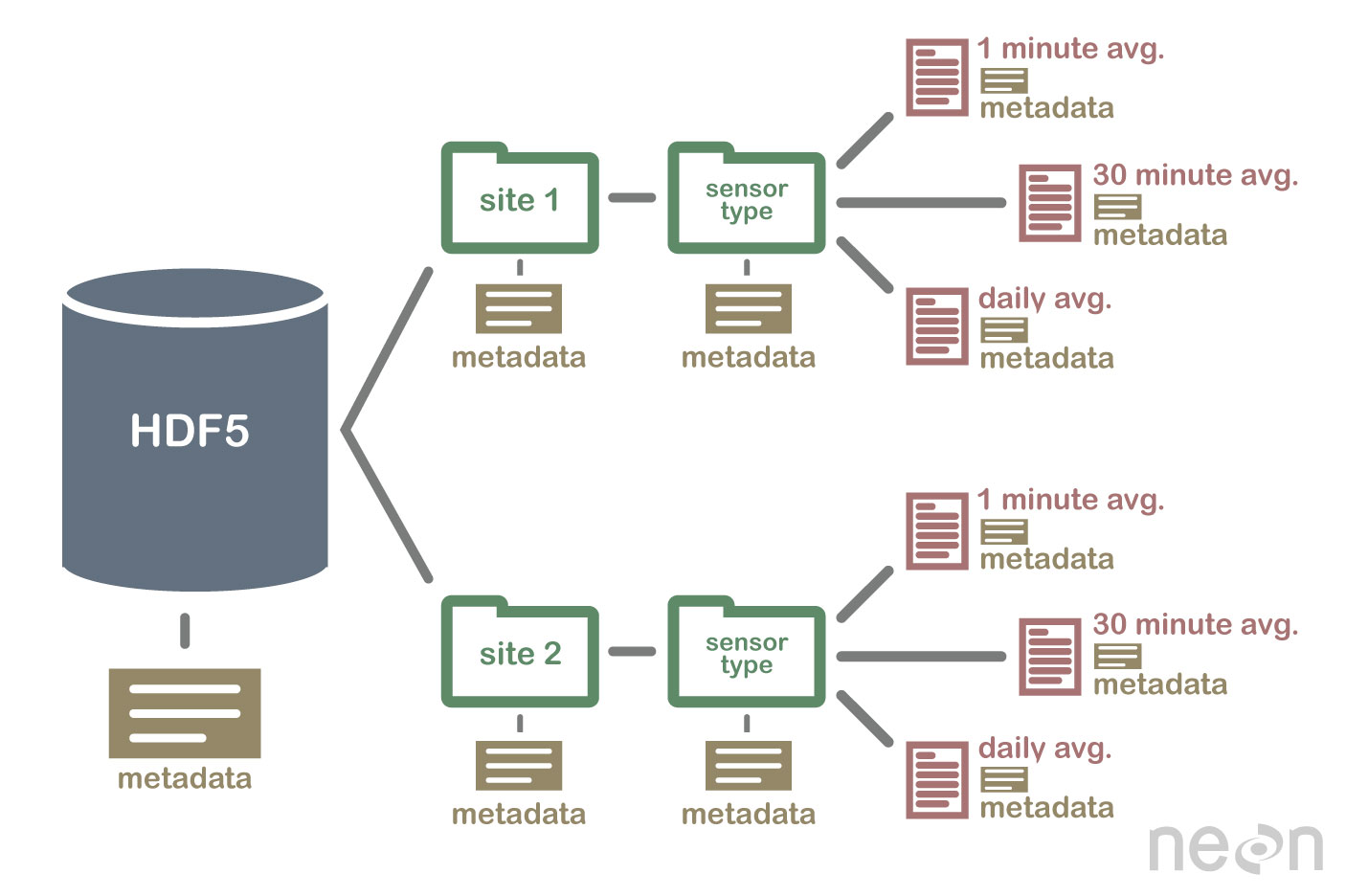
HDF5 is a Self Describing Format
HDF5 format is self describing. This means that each file, group and dataset can have associated metadata that describes exactly what the data are. Following the example above, we can embed information about each site to the file, such as:
- The full name and X,Y location of the site
- Description of the site.
- Any documentation of interest.
Similarly, we might add information about how the data in the dataset were collected, such as descriptions of the sensor used to collect the temperature data. We can also attach information, to each dataset within the site group, about how the averaging was performed and over what time period data are available.
One key benefit of having metadata that are attached to each file, group and
dataset, is that this facilitates automation without the need for a separate
(and additional) metadata document. Using a programming language, like R or
Python, we can grab information from the metadata that are already associated
with the dataset, and which we might need to process the dataset.
Compressed & Efficient subsetting
The HDF5 format is a compressed format. The size of all data contained within
HDF5 is optimized which makes the overall file size smaller. Even when
compressed, however, HDF5 files often contain big data and can thus still be
quite large. A powerful attribute of HDF5 is data slicing, by which a
particular subsets of a dataset can be extracted for processing. This means that
the entire dataset doesn't have to be read into memory (RAM); very helpful in
allowing us to more efficiently work with very large (gigabytes or more) datasets!
Heterogeneous Data Storage
HDF5 files can store many different types of data within in the same file. For example, one group may contain a set of datasets to contain integer (numeric) and text (string) data. Or, one dataset can contain heterogeneous data types (e.g., both text and numeric data in one dataset). This means that HDF5 can store any of the following (and more) in one file:
- Temperature, precipitation and PAR (photosynthetic active radiation) data for a site or for many sites
- A set of images that cover one or more areas (each image can have specific spatial information associated with it - all in the same file)
- A multi or hyperspectral spatial dataset that contains hundreds of bands.
- Field data for several sites characterizing insects, mammals, vegetation and meteorology.
- A set of images that cover one or more areas (each image can have unique spatial information associated with it)
- And much more!
Open Format
The HDF5 format is open and free to use. The supporting libraries (and a free
viewer), can be downloaded from the
HDF Group
website. As such, HDF5 is widely supported in a host of programs, including
open source programming languages like R and Python, and commercial
programming tools like Matlab and IDL. Spatial data that are stored in HDF5
format can be used in GIS and imaging programs including QGIS, ArcGIS, and
ENVI.
Summary Points - Benefits of HDF5
- Self-Describing The datasets with an HDF5 file are self describing. This allows us to efficiently extract metadata without needing an additional metadata document.
- Supporta Heterogeneous Data: Different types of datasets can be contained within one HDF5 file.
- Supports Large, Complex Data: HDF5 is a compressed format that is designed to support large, heterogeneous, and complex datasets.
- Supports Data Slicing: "Data slicing", or extracting portions of the dataset as needed for analysis, means large files don't need to be completely read into the computers memory or RAM.
-
Open Format - wide support in the many tools: Because the HDF5 format is
open, it is supported by a host of programming languages and tools, including
open source languages like R and
Pythonand open GIS tools likeQGIS.
HDFView: Exploring HDF5 Files in the Free HDFview Tool
Last Updated: Apr 8, 2021
In this tutorial you will use the free HDFView tool to explore HDF5 files and the groups and datasets contained within. You will also see how HDF5 files can be structured and explore metadata using both spatial and temporal data stored in HDF5!
Learning Objectives
After completing this activity, you will be able to:
- Explain how data can be structured and stored in HDF5.
- Navigate to metadata in an HDF5 file, making it "self describing".
- Explore HDF5 files using the free HDFView application.
Tools You Will Need
Install the free HDFView application. This application allows you to explore the contents of an HDF5 file easily. Click here to go to the download page.
Data to Download
NOTE: The first file downloaded has an .HDF5 file extension, the second file downloaded below has an .h5 extension. Both extensions represent the HDF5 data type.
NEON Teaching Data Subset: Sample Tower Temperature - HDF5
These temperature data were collected by the National Ecological Observatory Network's flux towers at field sites across the US. The entire dataset can be accessed by request from the NEON Data Portal.
Download DatasetDownload NEON Teaching Data Subset: Imaging Spectrometer Data - HDF5
These hyperspectral remote sensing data provide information on the National Ecological Observatory Network's San Joaquin Exerimental Range field site. The data were collected over the San Joaquin field site located in California (Domain 17) and processed at NEON headquarters. The entire dataset can be accessed by request from the NEON Data Portal.
Download DatasetInstalling HDFView
Select the HDFView download option that matches the operating system (Mac OS X, Windows, or Linux) and computer setup (32 bit vs 64 bit) that you have.
This tutorial was written with graphics from the VS 2012 version, but it is applicable to other versions as well.
Hierarchical Data Format 5 - HDF5
Hierarchical Data Format version 5 (HDF5), is an open file format that supports large, complex, heterogeneous data. Some key points about HDF5:
- HDF5 uses a "file directory" like structure.
- The HDF5 data models organizes information using
Groups. Each group may contain one or moredatasets. - HDF5 is a self describing file format. This means that the metadata for the data contained within the HDF5 file, are built into the file itself.
- One HDF5 file may contain several heterogeneous data types (e.g. images, numeric data, data stored as strings).
For more introduction to the HDF5 format, see our About Hierarchical Data Formats - What is HDF5? tutorial.
In this tutorial, we will explore two different types of data saved in HDF5. This will allow us to better understand how one file can store multiple different types of data, in different ways.
Part 1: Exploring Temperature Data in HDF5 Format in HDFView
The first thing that we will do is open an HDF5 file in the viewer to get a better idea of how HDF5 files can be structured.
Open a HDF5/H5 file in HDFView
To begin, open the HDFView application.
Within the HDFView application, select File --> Open and navigate to the folder
where you saved the NEONDSTowerTemperatureData.hdf5 file on your computer. Open this file in HDFView.
If you click on the name of the HDF5 file in the left hand window of HDFView, you can view metadata for the file. This will be located in the bottom window of the application.
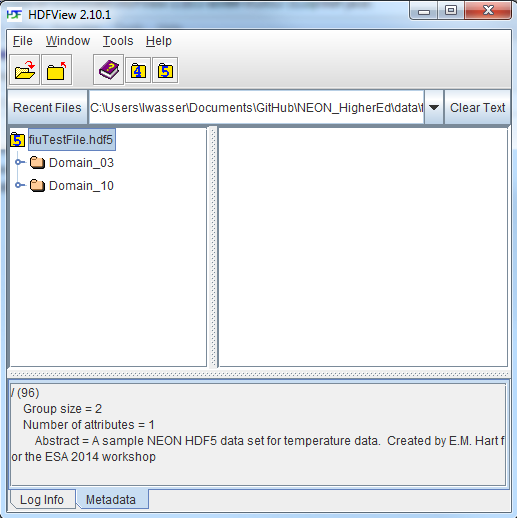
Explore File Structure in HDFView
Next, explore the structure of this file. Notice that there are two Groups (represented as folder icons in the viewer) called "Domain_03" and "Domain_10". Within each domain group, there are site groups (NEON sites that are located within those domains). Expand these folders by double clicking on the folder icons. Double clicking expands the groups content just as you might expand a folder in Windows explorer.
Notice that there is metadata associated with each group.
Double click on the OSBS group located within the Domain_03 group. Notice in
the metadata window that OSBS contains data collected from the
NEON Ordway-Swisher Biological Station field site.
Within the OSBS group there are two more groups - Min_1 and Min_30. What data
are contained within these groups?
Expand the "min_1" group within the OSBS site in Domain_03. Notice that there are five more nested groups named "Boom_1, 2, etc". A boom refers to an arm on a tower, which sits at a particular height and to which are attached sensors for collecting data on such variables as temperature, wind speed, precipitation, etc. In this case, we are working with data collected using temperature sensors, mounted on the tower booms.

Speaking of temperature - what type of sensor is collected the data within the boom_1 folder at the Ordway Swisher site? HINT: check the metadata for that dataset.
Expand the "Boom_1" folder by double clicking it. Finally, we have arrived at a dataset! Have a look at the metadata associated with the temperature dataset within the boom_1 group. Notice that there is metadata describing each attribute in the temperature dataset. Double click on the group name to open up the table in a tabular format. Notice that these data are temporal.
So this is one example of how an HDF5 file could be structured. This particular file contains data from multiple sites, collected from different sensors (mounted on different booms on the tower) and collected over time. Take some time to explore this HDF5 dataset within the HDFViewer.
Part 2: Exploring Hyperspectral Imagery stored in HDF5

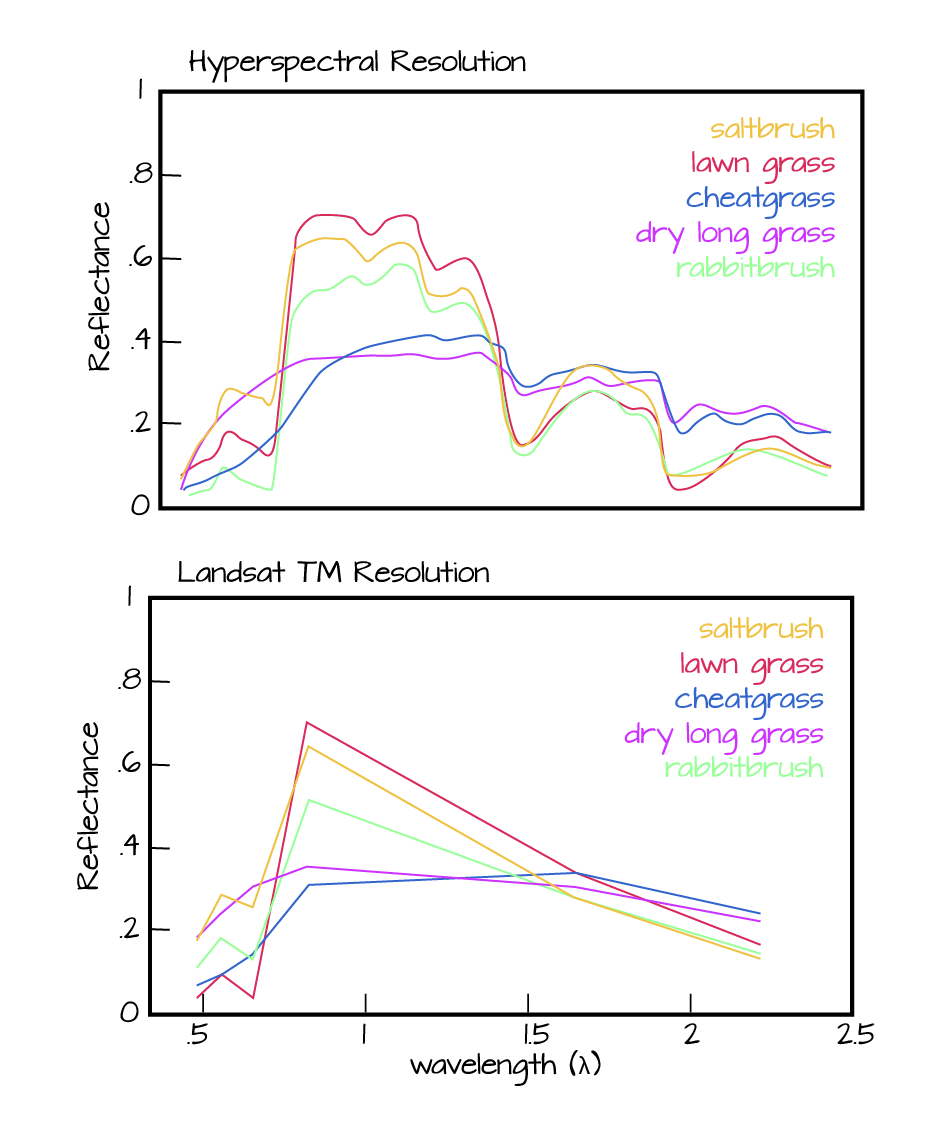
Next, we will explore a hyperspectral dataset, collected by the NEON Airborne Observation Platform (AOP) and saved in HDF5 format. Hyperspectral data are naturally hierarchical, as each pixel in the dataset contains reflectance values for hundreds of bands collected by the sensor. The NEON sensor (imaging spectrometer) collected data within 428 bands.
A few notes about hyperspectral imagery:
- An imaging spectrometer, which collects hyperspectral imagery, records light energy reflected off objects on the earth's surface.
- The data are inherently spatial. Each "pixel" in the image is located spatially and represents an area of ground on the earth.
- Similar to an Red, Green, Blue (RGB) camera, an imaging spectrometer records reflected light energy. Each pixel will contain several hundred bands worth of reflectance data.
Read more about hyperspectral remote sensing data:
Let's open some hyperspectral imagery stored in HDF5 format to see what the file structure can like for a different type of data.
Open the file. Notice that it is structured differently. This file is composed of 3 datasets:
- Reflectance,
- fwhm, and
- wavelength.
It also contains some text information called "map info". Finally it contains a group called spatial info.
Let's first look at the metadata stored in the spatialinfo group. This group contains all of the spatial information that a GIS program would need to project the data spatially.
Next, double click on the wavelength dataset. Note that this dataset contains the central wavelength value for each band in the dataset.
Finally, click on the reflectance dataset. Note that in the metadata for the dataset that the structure of the dataset is 426 x 501 x 477 (wavelength, line, sample), as indicated in the metadata. Right click on the reflectance dataset and select Open As. Click Image in the "display as" settings on the left hand side of the popup.
In this case, the image data are in the second and third dimensions of this dataset. However, HDFView will default to selecting the first and second dimensions
Let’s tell the HDFViewer to use the second and third dimensions to view the image:
- Under
height, make suredim 1is selected. - Under
width, make suredim 2is selected.
Notice an image preview appears on the left of the pop-up window. Click OK to open the image. You may have to play with the brightness and contrast settings in the viewer to see the data properly.
Explore the spectral dataset in the HDFViewer taking note of the metadata and data stored within the file.
Introduction to HDF5 Files in R
Last Updated: Nov 23, 2020
Learning Objectives
After completing this tutorial, you will be able to:
- Understand how HDF5 files can be created and structured in R using the rhdf5 libraries.
- Understand the three key HDF5 elements: the HDF5 file itself, groups, and datasets.
- Understand how to add and read attributes from an HDF5 file.
Things You’ll Need To Complete This Tutorial
To complete this tutorial you will need the most current version of R and, preferably, RStudio loaded on your computer.
R Libraries to Install:
- rhdf5: The rhdf5 package is hosted on Bioconductor not CRAN. Directions for installation are in the first code chunk.
More on Packages in R – Adapted from Software Carpentry.
Data to Download
We will use the file below in the optional challenge activity at the end of this tutorial.
NEON Teaching Data Subset: Field Site Spatial Data
These remote sensing data files provide information on the vegetation at the National Ecological Observatory Network's San Joaquin Experimental Range and Soaproot Saddle field sites. The entire dataset can be accessed by request from the NEON Data Portal.
Download DatasetSet Working Directory: This lesson assumes that you have set your working directory to the location of the downloaded and unzipped data subsets.
An overview of setting the working directory in R can be found here.
R Script & Challenge Code: NEON data lessons often contain challenges that reinforce learned skills. If available, the code for challenge solutions is found in the downloadable R script of the entire lesson, available in the footer of each lesson page.
Additional Resources
Consider reviewing the documentation for the RHDF5 package.
About HDF5
The HDF5 file can store large, heterogeneous datasets that include metadata. It
also supports efficient data slicing, or extraction of particular subsets of a
dataset which means that you don't have to read large files read into the
computers memory / RAM in their entirety in order work with them.
HDF5 in R
To access HDF5 files in R, we will use the rhdf5 library which is part of
the Bioconductor
suite of R libraries. It might also be useful to install
the
free HDF5 viewer
which will allow you to explore the contents of an HDF5 file using a graphic interface.
More about working with HDFview and a hands-on activity here.
First, let's get R setup. We will use the rhdf5 library. To access HDF5 files in R, we will use the rhdf5 library which is part of the Bioconductor suite of R packages. As of May 2020 this package was not yet on CRAN.
# Install rhdf5 package (only need to run if not already installed)
#install.packages("BiocManager")
#BiocManager::install("rhdf5")
# Call the R HDF5 Library
library("rhdf5")
# set working directory to ensure R can find the file we wish to import and where
# we want to save our files
wd <- "~/Git/data/" #This will depend on your local environment
setwd(wd)
Read more about the
rhdf5 package here.
Create an HDF5 File in R
Now, let's create a basic H5 file with one group and one dataset in it.
# Create hdf5 file
h5createFile("vegData.h5")
## [1] TRUE
# create a group called aNEONSite within the H5 file
h5createGroup("vegData.h5", "aNEONSite")
## [1] TRUE
# view the structure of the h5 we've created
h5ls("vegData.h5")
## group name otype dclass dim
## 0 / aNEONSite H5I_GROUP
Next, let's create some dummy data to add to our H5 file.
# create some sample, numeric data
a <- rnorm(n=40, m=1, sd=1)
someData <- matrix(a,nrow=20,ncol=2)
Write the sample data to the H5 file.
# add some sample data to the H5 file located in the aNEONSite group
# we'll call the dataset "temperature"
h5write(someData, file = "vegData.h5", name="aNEONSite/temperature")
# let's check out the H5 structure again
h5ls("vegData.h5")
## group name otype dclass dim
## 0 / aNEONSite H5I_GROUP
## 1 /aNEONSite temperature H5I_DATASET FLOAT 20 x 2
View a "dump" of the entire HDF5 file. NOTE: use this command with CAUTION if you are working with larger datasets!
# we can look at everything too
# but be cautious using this command!
h5dump("vegData.h5")
## $aNEONSite
## $aNEONSite$temperature
## [,1] [,2]
## [1,] 0.33155432 2.4054446
## [2,] 1.14305151 1.3329978
## [3,] -0.57253964 0.5915846
## [4,] 2.82950139 0.4669748
## [5,] 0.47549005 1.5871517
## [6,] -0.04144519 1.9470377
## [7,] 0.63300177 1.9532294
## [8,] -0.08666231 0.6942748
## [9,] -0.90739256 3.7809783
## [10,] 1.84223101 1.3364965
## [11,] 2.04727590 1.8736805
## [12,] 0.33825921 3.4941913
## [13,] 1.80738042 0.5766373
## [14,] 1.26130759 2.2307994
## [15,] 0.52882731 1.6021497
## [16,] 1.59861449 0.8514808
## [17,] 1.42037674 1.0989390
## [18,] -0.65366487 2.5783750
## [19,] 1.74865593 1.6069304
## [20,] -0.38986048 -1.9471878
# Close the file. This is good practice.
H5close()
Add Metadata (attributes)
Let's add some metadata (called attributes in HDF5 land) to our dummy temperature data. First, open up the file.
# open the file, create a class
fid <- H5Fopen("vegData.h5")
# open up the dataset to add attributes to, as a class
did <- H5Dopen(fid, "aNEONSite/temperature")
# Provide the NAME and the ATTR (what the attribute says) for the attribute.
h5writeAttribute(did, attr="Here is a description of the data",
name="Description")
h5writeAttribute(did, attr="Meters",
name="Units")
Now we can add some attributes to the file.
# let's add some attributes to the group
did2 <- H5Gopen(fid, "aNEONSite/")
h5writeAttribute(did2, attr="San Joaquin Experimental Range",
name="SiteName")
h5writeAttribute(did2, attr="Southern California",
name="Location")
# close the files, groups and the dataset when you're done writing to them!
H5Dclose(did)
H5Gclose(did2)
H5Fclose(fid)
Working with an HDF5 File in R
Now that we've created our H5 file, let's use it! First, let's have a look at the attributes of the dataset and group in the file.
# look at the attributes of the precip_data dataset
h5readAttributes(file = "vegData.h5",
name = "aNEONSite/temperature")
## $Description
## [1] "Here is a description of the data"
##
## $Units
## [1] "Meters"
# look at the attributes of the aNEONsite group
h5readAttributes(file = "vegData.h5",
name = "aNEONSite")
## $Location
## [1] "Southern California"
##
## $SiteName
## [1] "San Joaquin Experimental Range"
# let's grab some data from the H5 file
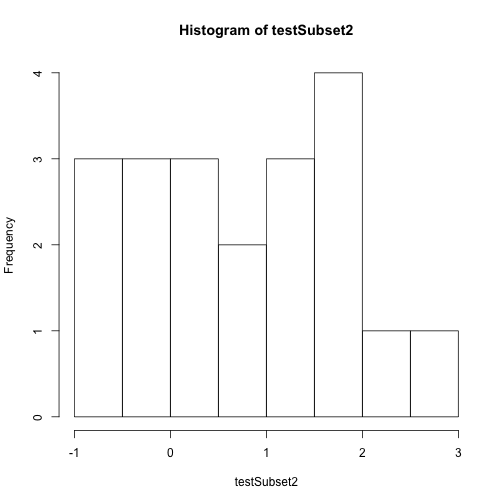
testSubset <- h5read(file = "vegData.h5",
name = "aNEONSite/temperature")
testSubset2 <- h5read(file = "vegData.h5",
name = "aNEONSite/temperature",
index=list(NULL,1))
H5close()
Once we've extracted data from our H5 file, we can work with it in R.
# create a quick plot of the data
hist(testSubset2)
Time to practice the skills you've learned. Open up the D17_2013_SJER_vegStr.csv in R.
- Create a new HDF5 file called
vegStructure. - Add a group in your HDF5 file called
SJER. - Add the veg structure data to that folder.
- Add some attributes the SJER group and to the data.
- Now, repeat the above with the D17_2013_SOAP_vegStr csv.
- Name your second group SOAP
Hint: read.csv() is a good way to read in .csv files.
Get Lesson Code
Create HDF5 Files in R Using Loops
Last Updated: Apr 8, 2021
Subsetting NEON HDF5 hyperspectral files to reduce file size
Last Updated: Nov 26, 2020
In this tutorial, we will subset an existing HDF5 file containing NEON hyperspectral data. The purpose of this exercise is to generate a smaller file for use in subsequent analyses to reduce the file transfer time and processing power needed.
Learning Objectives
After completing this activity, you will be able to:
- Navigate an HDF5 file to identify the variables of interest.
- Generate a new HDF5 file from a subset of the existing dataset.
- Save the new HDF5 file for future use.
Things You’ll Need To Complete This Tutorial
To complete this tutorial you will need the most current version of R and, preferably, RStudio loaded on your computer.
R Libraries to Install:
-
rhdf5:
install.packages("BiocManager"),BiocManager::install("rhdf5") -
raster:
install.packages('raster')
More on Packages in R - Adapted from Software Carpentry.
Data to Download
The purpose of this tutorial is to reduce a large file (~652Mb) to a smaller
size. The download linked here is the original large file, and therefore you may
choose to skip this tutorial and download if you are on a slow internet connection
or have file size limitations on your device.
Download NEON Teaching Dataset: Full Tile Imaging Spectrometer Data - HDF5 (652Mb)
These hyperspectral remote sensing data provide information on the National Ecological Observatory Network's San Joaquin Exerimental Range field site.
These data were collected over the San Joaquin field site located in California (Domain 17) in March of 2019 and processed at NEON headquarters. This particular mosaic tile is named NEON_D17_SJER_DP3_257000_4112000_reflectance.h5. The entire dataset can be accessed by request from the NEON Data Portal.
Download DatasetSet Working Directory: This lesson assumes that you have set your working directory to the location of the downloaded and unzipped data subsets.
An overview of setting the working directory in R can be found here.
R Script & Challenge Code: NEON data lessons often contain challenges that reinforce learned skills. If available, the code for challenge solutions is found in the downloadable R script of the entire lesson, available in the footer of each lesson page.
Recommended Skills
For this tutorial, we recommend that you have some basic familiarity with the HDF5 file format, including knowing how to open HDF5 files (in Rstudio or HDF5Viewer) and how groups and metadata are structured. To brush up on these skills, we suggest that you work through the Introduction to Working with HDF5 Format in R series before moving on to this tutorial.
Why subset your dataset?
There are many reasons why you may wish to subset your HDF5 file. Primarily, HDF5 files may contain a large amount of information that is not necessary for your purposes. By subsetting the file, you can reduce file size, thereby shrinking your storage needs, shortening file transfer/download times, and reducing your processing time for analysis. In this example, we will take a full HDF5 file of NEON hyperspectral reflectance data from the San Joaquin Experimental Range (SJER) that has a file size of ~652 Mb and make a new HDF5 file with a reduced spatial extent, and a reduced spectral resolution, yielding a file of only ~50.1 Mb. This reduction in file size will make it easier and faster to conduct your analysis and to share your data with others. We will then use this subsetted file in the Introduction to Hyperspectral Remote Sensing Data series.
If you find that downloading the full 652 Mb file takes too much time or storage space, you will find a link to this subsetted file at the top of each lesson in the Introduction to Hyperspectral Remote Sensing Data series.
Exploring the NEON hyperspectral HDF5 file structure
In order to determine what information that we want to put into our subset, we should first take a look at the full NEON hyperspectral HDF5 file structure to see what is included. To do so, we will load the required package for this tutorial (you can un-comment the middle two lines to load 'BiocManager' and 'rhdf5' if you don't already have it on your computer).
# Install rhdf5 package (only need to run if not already installed)
# install.packages("BiocManager")
# BiocManager::install("rhdf5")
# Load required packages
library(rhdf5)
Next, we define our working directory where we have saved the full HDF5
file of NEON hyperspectral reflectance data from the SJER site. Note,
the filepath to the working directory will depend on your local environment.
Then, we create a string (f) of the HDF5 filename and read its attributes.
# set working directory to ensure R can find the file we wish to import and where
# we want to save our files. Be sure to move the download into your working directory!
wd <- "~/Documents/data/" # This will depend on your local environment
setwd(wd)
# Make the name of our HDF5 file a variable
f_full <- paste0(wd,"NEON_D17_SJER_DP3_257000_4112000_reflectance.h5")
Next, let's take a look at the structure of the full NEON hyperspectral reflectance HDF5 file.
View(h5ls(f_full, all=T))
Wow, there is a lot of information in there! The majority of the groups contained within this file are Metadata, most of which are used for processing the raw observations into the reflectance product that we want to use. For demonstration and teaching purposes, we will not need this information. What we will need are things like the Coordinate_System information (so that we can georeference these data), the Wavelength dataset (so that we can match up each band with its appropriate wavelength in the electromagnetic spectrum), and of course the Reflectance_Data themselves. You can also see that each group and dataset has a number of associated attributes (in the 'num_attrs' column). We will want to copy over those attributes into the data subset as well. But first, we need to define each of the groups that we want to populate in our new HDF5 file.
Create new HDF5 file framework
In order to make a new subset HDF5 file, we first must create an empty file
with the appropriate name, then we will begin to fill in that file with the
essential data and attributes that we want to include. Note that the function
h5createFile() will not overwrite an existing file. Therefore, if you have
already created or downloaded this file, the function will throw an error!
Each function should return 'TRUE' if it runs correctly.
# First, create a name for the new file
f <- paste0(wd, "NEON_hyperspectral_tutorial_example_subset.h5")
# create hdf5 file
h5createFile(f)
## [1] TRUE
# Now we create the groups that we will use to organize our data
h5createGroup(f, "SJER/")
## [1] TRUE
h5createGroup(f, "SJER/Reflectance")
## [1] TRUE
h5createGroup(f, "SJER/Reflectance/Metadata")
## [1] TRUE
h5createGroup(f, "SJER/Reflectance/Metadata/Coordinate_System")
## [1] TRUE
h5createGroup(f, "SJER/Reflectance/Metadata/Spectral_Data")
## [1] TRUE
Adding group attributes
One of the great things about HDF5 files is that they can contain
data and attributes within the same group.
As explained within the Introduction to Working with HDF5 Format in R series,
attributes are a type of metadata that are associated with an HDF5 group or
dataset. There may be multiple attributes associated with each group and/or
dataset. Attributes come with a name and an associated array of information.
In this tutorial, we will read the existing attribute data from the full
hyperspectral tile using the h5readAttributes() function (which returns
a list of attributes), then we loop through those attributes and write
each attribute to its appropriate group using the h5writeAttribute() function.
First, we will do this for the low-level "SJER/Reflectance" group. In this step,
we are adding attributes to a group rather than a dataset. To do so, we must
first open a file and group interface using the H5Fopen and H5Gopen functions,
then we can use h5writeAttribute() to edit the group that we want to give
an attribute.
a <- h5readAttributes(f_full,"/SJER/Reflectance/")
fid <- H5Fopen(f)
g <- H5Gopen(fid, "SJER/Reflectance")
for(i in 1:length(names(a))){
h5writeAttribute(attr = a[[i]], h5obj=g, name=names(a[i]))
}
# It's always a good idea to close the file connection immidiately
# after finishing each step that leaves an open connection.
h5closeAll()
Next, we will loop through each of the datasets within the Coordinate_System group, and copy those (and their attributes, if present) from the full tile to our subset file. The Coordinate_System group contains many important pieces of information for geolocating our data, so we need to make sure that the subset file has that information.
# make a list of all groups within the full tile file
ls <- h5ls(f_full,all=T)
# make a list of all of the names within the Coordinate_System group
cg <- unique(ls[ls$group=="/SJER/Reflectance/Metadata/Coordinate_System",]$name)
# Loop through the list of datasets that we just made above
for(i in 1:length(cg)){
print(cg[i])
# Read the inividual dataset within the Coordinate_System group
d=h5read(f_full,paste0("/SJER/Reflectance/Metadata/Coordinate_System/",cg[i]))
# Read the associated attributes (if any)
a=h5readAttributes(f_full,paste0("/SJER/Reflectance/Metadata/Coordinate_System/",cg[i]))
# Assign the attributes (if any) to the dataset
attributes(d)=a
# Finally, write the dataset to the HDF5 file
h5write(obj=d,file=f,
name=paste0("/SJER/Reflectance/Metadata/Coordinate_System/",cg[i]),
write.attributes=T)
}
## [1] "Coordinate_System_String"
## [1] "EPSG Code"
## [1] "Map_Info"
## [1] "Proj4"
Spectral Subsetting
The goal of subsetting this dataset is to substantially reduce the file size, making it faster to download and process these data. While each AOP mosaic tile is not particularly large in terms of its spatial scale (1km by 1km at 1m resolution= 1,000,000 pixels, or about half as many pixels at shown on a standard 1080p computer screen), the 426 spectral bands available result in a fairly large file size. Therefore, we will reduce the spectral resolution of these data by selecting every fourth band in the dataset, which reduces the file size to 1/4 of the original!
Some circumstances demand the full spectral resolution file. For example, if you wanted to discern between the spectral signatures of similar minerals, or if you were conducting an analysis of the differences in the 'red edge' between plant functional types, you would want to use the full spectral resolution of the original hyperspectral dataset. Still, we can use far fewer bands for demonstration and teaching purposes, while still getting a good sense of what these hyperspectral data can do.
# First, we make our 'index', a list of number that will allow us to select every fourth band, using the "sequence" function seq()
idx <- seq(from = 1, to = 426, by = 4)
# We then use this index to select particular wavelengths from the full tile using the "index=" argument
wavelengths <- h5read(file = f_full,
name = "SJER/Reflectance/Metadata/Spectral_Data/Wavelength",
index = list(idx)
)
# As per above, we also need the wavelength attributes
wavelength.attributes <- h5readAttributes(file = f_full,
name = "SJER/Reflectance/Metadata/Spectral_Data/Wavelength")
attributes(wavelengths) <- wavelength.attributes
# Finally, write the subset of wavelengths and their attributes to the subset file
h5write(obj=wavelengths, file=f,
name="SJER/Reflectance/Metadata/Spectral_Data/Wavelength",
write.attributes=T)
Spatial Subsetting
Even after spectral subsetting, our file size would be greater than 100Mb.
herefore, we will also perform a spatial subsetting process to further
reduce our file size. Now, we need to figure out which part of the full image
that we want to extract for our subset. It takes a number of steps in order
to read in a band of data and plot the reflectance values - all of which are
thoroughly described in the Intro to Working with Hyperspectral Remote Sensing Data in HDF5 Format in R
tutorial. For now, let's focus on the essentials for our problem at hand. In
order to explore the spatial qualities of this dataset, let's plot a single
band as an overview map to see what objects and land cover types are contained
within this mosaic tile. The Reflectance_Data dataset has three dimensions in
the order of bands, columns, rows. We want to extract a single band, and all
1,000 columns and rows, so we will feed those values into the index= argument
as a list. For this example, we will select the 58th band in the hyperspectral
dataset, which corresponds to a wavelength of 667nm, which is in the red end of
the visible electromagnetic spectrum. We will use NULL in the column and row
position to indicate that we want all of the columns and rows (we agree that
it is weird that NULL indicates "all" in this circumstance, but that is the
default behavior for this, and many other, functions).
# Extract or "slice" data for band 58 from the HDF5 file
b58 <- h5read(f_full,name = "SJER/Reflectance/Reflectance_Data",
index=list(58,NULL,NULL))
h5closeAll()
# convert from array to matrix
b58 <- b58[1,,]
# Make a plot to view this band
image(log(b58), col=grey(0:100/100))
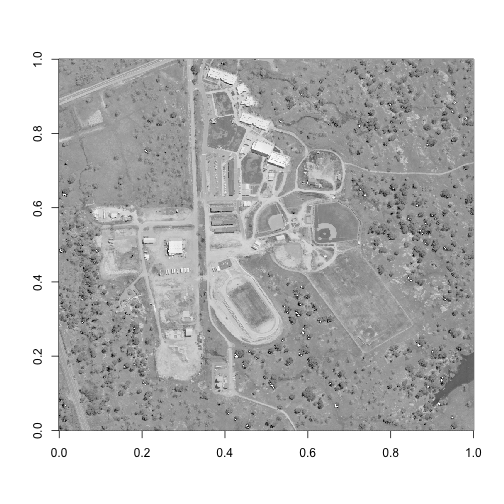
As we can see here, this hyperspectral reflectance tile contains a school campus that is under construction. There are many different land cover types contained here, which makes it a great example! Perhaps the most unique feature shown is in the bottom right corner of this image, where we can see the tip of a small reservoir. Let's be sure to capture this feature in our spatial subset, as well as a few other land cover types (irrigated grass, trees, bare soil, and buildings).
While raster images count their pixels from the top left corner, we are working
with a matrix, which counts its pixels from the bottom left corner. Therefore,
rows are counted from the bottom to the top, and columns are counted from the
left to the right. If we want to sample the bottom right quadrant of this image,
we need to select rows 1 through 500 (bottom half), and columns 501 through 1000
(right half). Note that, as above, the index= argument in h5read() requires
a list of three dimensions for this example - in the order of bands, columns,
rows.
subset_rows <- 1:500
subset_columns <- 501:1000
# Extract or "slice" data for band 44 from the HDF5 file
b58 <- h5read(f_full,name = "SJER/Reflectance/Reflectance_Data",
index=list(58,subset_columns,subset_rows))
h5closeAll()
# convert from array to matrix
b58 <- b58[1,,]
# Make a plot to view this band
image(log(b58), col=grey(0:100/100))

Perfect - now we have a spatial subset that includes all of the different land cover types that we are interested in investigating.
-
Pick your own area of interest for this spatial subset, and find the rows and columns that capture that area. Can you include some solar panels, as well as the water body?
-
Does it make a difference if you use a band from another part of the electromagnetic spectrum, such as the near-infrared? Hint: you can use the 'wavelengths' function above while removing the
index=argument to get the full list of band wavelengths.
Extracting a subset
Now that we have determined our ideal spectral and spatial subsets for our
analysis, we are ready to put both of those pieces of information into our
h5read() function to extract our example subset out of the full NEON
hyperspectral dataset. Here, we are taking every fourth band (using our idx
variabe), columns 501:1000 (the right half of the tile) and rows 1:500 (the
bottom half of the tile). The results in us extracting every fourth band of
the bottom-right quadrant of the mosaic tile.
# Read in reflectance data.
# Note the list that we feed into the index argument!
# This tells the h5read() function which bands, rows, and
# columns to read. This is ultimately how we reduce the file size.
hs <- h5read(file = f_full,
name = "SJER/Reflectance/Reflectance_Data",
index = list(idx, subset_columns, subset_rows)
)
As per the 'adding group attributes' section above, we will need to add the
attributes to the hyperspectral data (hs) before writing to the new HDF5
subset file (f). The hs variable already has one attribute, $dim, which
contains the actual dimensions of the hs array, and will be important for
writing the array to the f file later. We will want to combine this attribute
with all of the other Reflectance_Data group attributes from the original HDF5
file, f. However, some of the attributes will no longer be valid, such as the
Dimensions and Spatial_Extent_meters attributes, so we will need to overwrite
those before assigning these attributes to the hs variable to then write to
the f file.
# grab the '$dim' attribute - as this will be needed
# when writing the file at the bottom
hsd <- attributes(hs)
# We also need the attributes for the reflectance data.
ha <- h5readAttributes(file = f_full,
name = "SJER/Reflectance/Reflectance_Data")
# However, some of the attributes are not longer valid since
# we changed the spatial extend of this dataset. therefore,
# we will need to overwrite those with the correct values.
ha$Dimensions <- c(500,500,107) # Note that the HDF5 file saves dimensions in a different order than R reads them
ha$Spatial_Extent_meters[1] <- ha$Spatial_Extent_meters[1]+500
ha$Spatial_Extent_meters[3] <- ha$Spatial_Extent_meters[3]+500
attributes(hs) <- c(hsd,ha)
# View the combined attributes to ensure they are correct
attributes(hs)
## $dim
## [1] 107 500 500
##
## $Cloud_conditions
## [1] "For cloud conditions information see Weather Quality Index dataset."
##
## $Cloud_type
## [1] "Cloud type may have been selected from multiple flight trajectories."
##
## $Data_Ignore_Value
## [1] -9999
##
## $Description
## [1] "Atmospherically corrected reflectance."
##
## $Dimension_Labels
## [1] "Line, Sample, Wavelength"
##
## $Dimensions
## [1] 500 500 107
##
## $Interleave
## [1] "BSQ"
##
## $Scale_Factor
## [1] 10000
##
## $Spatial_Extent_meters
## [1] 257500 258000 4112500 4113000
##
## $Spatial_Resolution_X_Y
## [1] 1 1
##
## $Units
## [1] "Unitless."
##
## $Units_Valid_range
## [1] 0 10000
# Finally, write the hyperspectral data, plus attributes,
# to our new file 'f'.
h5write(obj=hs, file=f,
name="SJER/Reflectance/Reflectance_Data",
write.attributes=T)
## You created a large dataset with compression and chunking.
## The chunk size is equal to the dataset dimensions.
## If you want to read subsets of the dataset, you should testsmaller chunk sizes to improve read times.
# It's always a good idea to close the HDF5 file connection
# before moving on.
h5closeAll()
That's it! We just created a subset of the original HDF5 file, and included the most essential groups and metadata for exploratory analysis. You may consider adding other information, such as the weather quality indicator, when subsetting datasets for your own purposes.
If you want to take a look at the subset that you just made, run the h5ls() function:
View(h5ls(f, all=T))