Workshop
Using NEON Data and Teaching Materials with Your Students
BioQuest Summer Workshop: Wicked Problems
Data discovery, manipulation, and analysis are crucial skills for students to be comfortable asking questions using data. As an instructor, you want to be able to use or build teaching materials around data sets that can be used year after year. The standardized data collection and delivery methods for over 180 different data products from the National Ecological Observatory Network (NEON) allow you to use public OERs or build your own materials for your classroom knowing that the same data will be available next year. With this free, standardized data from 81 different NEON field sites from across the US, you can find local or regional data and have students make comparisons across the continent. NEON data can be used at many skill levels; existing OER materials from NEON range from a focus on interpretation of figures to spreadsheet use to reproducible, programming-based data analysis.
In this workshop session, we will spend the first hour exploring open educational resources that use NEON data, with an emphasis on Data Management using NEON’s Small Mammal Data with Accompanying Lesson on Mark Recapture Analysis (McNeil & Jones, 2018). In the second hour, we will use the NEON data portal to directly access NEON data of interest with a discussion of considerations for using the NEON portal and data with students. Participants will leave this session with the tools and comfort level to discover and access data from the NEON data portal and to be aware of and able to use the open educational resources available from NEON.
This session will be presented as a guided navigation through the available resources, therefore, workshop participants should bring a laptop with Excel or Google Sheets (tablets and phones are not ideal) to be able to participate fully in the workshop.
You can also view session information on the BioQuest Summer Workshop page.
During the first hour of the workshop, we will watch a short video on the National Ecological Observatory Network and answer participant's questions on the project. Then, we will focus on open educational resources using NEON data, in particular the Data Management using NEON Small Mammal Data module (below).
NEON: Data to Understand Changing Ecosystems
Teaching Module
Data Management using NEON Small Mammal Data
During the second hour of the workshop, we will focus on accessing data from the NEON data portal. We will also preview the neonUtilities R package available from NEONScience on GitHub. Details on how to use the package in the tutorial below.
Use the neonUtilities Package to Access NEON Data
Using neonUtilities in Python
The instructions below will guide you through using the neonUtilities R package in Python, via the rpy2 package. rpy2 creates an R environment you can interact with from Python.
The assumption in this tutorial is that you want to work with NEON data in
Python, but you want to use the handy download and merge functions provided by
the neonUtilities R package to access and format the data for analysis. If
you want to do your analyses in R, use one of the R-based tutorials linked
below.
For more information about the neonUtilities package, and instructions for
running it in R directly, see the Download and Explore tutorial
and/or the neonUtilities tutorial.
Install and set up
Before starting, you will need:
- Python 3 installed. It is probably possible to use this workflow in Python 2, but these instructions were developed and tested using 3.7.4.
- R installed. You don't need to have ever used it directly. We wrote this tutorial using R 4.1.1, but most other recent versions should also work.
-
rpy2installed. Run the line below from the command line, it won't run within a Python script. See Python documentation for more information on how to install packages.rpy2often has install problems on Windows, see "Windows Users" section below if you are running Windows. - You may need to install
pipbefore installingrpy2, if you don't have it installed already.
From the command line, run pip install rpy2
Windows users
The rpy2 package was built for Mac, and doesn't always work smoothly on Windows. If you have trouble with the install, try these steps.
- Add C:\Program Files\R\R-3.3.1\bin\x64 to the Windows Environment Variable “Path”
- Install rpy2 manually from https://www.lfd.uci.edu/~gohlke/pythonlibs/#rpy2
- Pick the correct version. At the download page the portion of the files with cp## relate to the Python version. e.g., rpy2 2.9.2 cp36 cp36m win_amd64.whl is the correct download when 2.9.2 is the latest version of rpy2 and you are running Python 36 and 64 bit Windows (amd64).
- Save the whl file, navigate to it in windows then run pip directly on the file as follows “pip install rpy2 2.9.2 cp36 cp36m win_amd64.whl”
- Add an R_HOME Windows environment variable with the path C:\Program Files\R\R-3.4.3 (or whichever version you are running)
- Add an R_USER Windows environment variable with the path C:\Users\yourUserName\AppData\Local\Continuum\Anaconda3\Lib\site-packages\rpy2
Additional troubleshooting
If you're still having trouble getting R to communicate with Python, you can try pointing Python directly to your R installation path.
- Run
R.home()in R. - Run
import osin Python. - Run
os.environ['R_HOME'] = '/Library/Frameworks/R.framework/Resources'in Python, substituting the file path you found in step 1.
Load packages
Now open up your Python interface of choice (Jupyter notebook, Spyder, etc) and import rpy2 into your session.
import rpy2
import rpy2.robjects as robjects
from rpy2.robjects.packages import importr
Load the base R functionality, using the rpy2 function importr().
base = importr('base')
utils = importr('utils')
stats = importr('stats')
The basic syntax for running R code via rpy2 is package.function(inputs),
where package is the R package in use, function is the name of the function
within the R package, and inputs are the inputs to the function. In other
words, it's very similar to running code in R as package::function(inputs).
For example:
stats.rnorm(6, 0, 1)
FloatVector with 6 elements.
Suppress R warnings. This step can be skipped, but will result in messages getting passed through from R that Python will interpret as warnings.
from rpy2.rinterface_lib.callbacks import logger as rpy2_logger
import logging
rpy2_logger.setLevel(logging.ERROR)
Install the neonUtilities R package. Here I've specified the RStudio
CRAN mirror as the source, but you can use a different one if you
prefer.
You only need to do this step once to use the package, but we update
the neonUtilities package every few months, so reinstalling
periodically is recommended.
This installation step carries out the same steps in the same places on
your hard drive that it would if run in R directly, so if you use R
regularly and have already installed neonUtilities on your machine,
you can skip this step. And be aware, this also means if you install
other packages, or new versions of packages, via rpy2, they'll
be updated the next time you use R, too.
The semicolon at the end of the line (here, and in some other function calls below) can be omitted. It suppresses a note indicating the output of the function is null. The output is null because these functions download or modify files on your local drive, but none of the data are read into the Python or R environments.
utils.install_packages('neonUtilities', repos='https://cran.rstudio.com/');
The downloaded binary packages are in
/var/folders/_k/gbjn452j1h3fk7880d5ppkx1_9xf6m/T//Rtmpl5OpMA/downloaded_packages
Now load the neonUtilities package. This does need to be run every time
you use the code; if you're familiar with R, importr() is roughly
equivalent to the library() function in R.
neonUtilities = importr('neonUtilities')
Join data files: stackByTable()
The function stackByTable() in neonUtilities merges the monthly,
site-level files the NEON Data Portal
provides. Start by downloading the dataset you're interested in from the
Portal. Here, we'll assume you've downloaded IR Biological Temperature.
It will download as a single zip file named NEON_temp-bio.zip. Note the
file path it's saved to and proceed.
Run the stackByTable() function to stack the data. It requires only one
input, the path to the zip file you downloaded from the NEON Data Portal.
Modify the file path in the code below to match the path on your machine.
For additional, optional inputs to stackByTable(), see the R tutorial
for neonUtilities.
neonUtilities.stackByTable(filepath='/Users/Shared/NEON_temp-bio.zip');
Stacking operation across a single core.
Stacking table IRBT_1_minute
Stacking table IRBT_30_minute
Merged the most recent publication of sensor position files for each site and saved to /stackedFiles
Copied the most recent publication of variable definition file to /stackedFiles
Finished: Stacked 2 data tables and 3 metadata tables!
Stacking took 2.019079 secs
All unzipped monthly data folders have been removed.
Check the folder containing the original zip file from the Data Portal;
you should now have a subfolder containing the unzipped and stacked files
called stackedFiles. To import these data to Python, skip ahead to the
"Read downloaded and stacked files into Python" section; to learn how to
use neonUtilities to download data, proceed to the next section.
Download files to be stacked: zipsByProduct()
The function zipsByProduct() uses the NEON API to programmatically download
data files for a given product. The files downloaded by zipsByProduct()
can then be fed into stackByTable().
Run the downloader with these inputs: a data product ID (DPID), a set of 4-letter site IDs (or "all" for all sites), a download package (either basic or expanded), the filepath to download the data to, and an indicator to check the size of your download before proceeding or not (TRUE/FALSE).
The DPID is the data product identifier, and can be found in the data product box on the NEON Explore Data page. Here we'll download Breeding landbird point counts, DP1.10003.001.
There are two differences relative to running zipsByProduct() in R directly:
-
check.sizebecomescheck_size, because dots have programmatic meaning in Python -
TRUE(orT) becomes'TRUE'because the values TRUE and FALSE don't have special meaning in Python the way they do in R, so it interprets them as variables if they're unquoted.
check_size='TRUE' does not work correctly in the Python environment. In R,
it estimates the size of the download and asks you to confirm before
proceeding, and the interactive question and answer don't work correctly
outside R. Set check_size='FALSE' to avoid this problem, but be thoughtful
about the size of your query since it will proceed to download without checking.
neonUtilities.zipsByProduct(dpID='DP1.10003.001',
site=base.c('HARV','BART'),
savepath='/Users/Shared',
package='basic',
check_size='FALSE');
Finding available files
|======================================================================| 100%
Downloading files totaling approximately 4.217543 MB
Downloading 18 files
|======================================================================| 100%
18 files successfully downloaded to /Users/Shared/filesToStack10003
The message output by zipsByProduct() indicates the file path where the
files have been downloaded.
Now take that file path and pass it to stackByTable().
neonUtilities.stackByTable(filepath='/Users/Shared/filesToStack10003');
Unpacking zip files using 1 cores.
Stacking operation across a single core.
Stacking table brd_countdata
Stacking table brd_perpoint
Copied the most recent publication of validation file to /stackedFiles
Copied the most recent publication of categoricalCodes file to /stackedFiles
Copied the most recent publication of variable definition file to /stackedFiles
Finished: Stacked 2 data tables and 4 metadata tables!
Stacking took 0.4586661 secs
All unzipped monthly data folders have been removed.
Read downloaded and stacked files into Python
We've downloaded biological temperature and bird data, and merged the site by month files. Now let's read those data into Python so you can proceed with analyses.
First let's take a look at what's in the output folders.
import os
os.listdir('/Users/Shared/filesToStack10003/stackedFiles/')
['categoricalCodes_10003.csv',
'issueLog_10003.csv',
'brd_countdata.csv',
'brd_perpoint.csv',
'readme_10003.txt',
'variables_10003.csv',
'validation_10003.csv']
os.listdir('/Users/Shared/NEON_temp-bio/stackedFiles/')
['IRBT_1_minute.csv',
'sensor_positions_00005.csv',
'issueLog_00005.csv',
'IRBT_30_minute.csv',
'variables_00005.csv',
'readme_00005.txt']
Each data product folder contains a set of data files and metadata files. Here, we'll read in the data files and take a look at the contents; for more details about the contents of NEON data files and how to interpret them, see the Download and Explore tutorial.
There are a variety of modules and methods for reading tabular data into
Python; here we'll use the pandas module, but feel free to use your own
preferred method.
First, let's read in the two data tables in the bird data:
brd_countdata and brd_perpoint.
import pandas
brd_perpoint = pandas.read_csv('/Users/Shared/filesToStack10003/stackedFiles/brd_perpoint.csv')
brd_countdata = pandas.read_csv('/Users/Shared/filesToStack10003/stackedFiles/brd_countdata.csv')
And take a look at the contents of each file. For descriptions and unit of each
column, see the variables_10003 file.
brd_perpoint
| uid | namedLocation | domainID | siteID | plotID | plotType | pointID | nlcdClass | decimalLatitude | decimalLongitude | ... | endRH | observedHabitat | observedAirTemp | kmPerHourObservedWindSpeed | laboratoryName | samplingProtocolVersion | remarks | measuredBy | publicationDate | release | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 32ab1419-b087-47e1-829d-b1a67a223a01 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | C1 | evergreenForest | 44.060146 | -71.315479 | ... | 56.0 | evergreen forest | 18.0 | 1.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vG | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 1 | f02e2458-caab-44d8-a21a-b3b210b71006 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | B1 | evergreenForest | 44.060146 | -71.315479 | ... | 56.0 | deciduous forest | 19.0 | 3.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vG | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 2 | 58ccefb8-7904-4aa6-8447-d6f6590ccdae | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | A1 | evergreenForest | 44.060146 | -71.315479 | ... | 56.0 | mixed deciduous/evergreen forest | 17.0 | 0.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vG | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 3 | 1b14ead4-03fc-4d47-bd00-2f6e31cfe971 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | A2 | evergreenForest | 44.060146 | -71.315479 | ... | 56.0 | deciduous forest | 19.0 | 0.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vG | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 4 | 3055a0a5-57ae-4e56-9415-eeb7704fab02 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | B2 | evergreenForest | 44.060146 | -71.315479 | ... | 56.0 | deciduous forest | 16.0 | 0.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vG | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1405 | 56d2f3b3-3ee5-41b9-ae22-e78a814d83e4 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | A2 | evergreenForest | 42.451400 | -72.250100 | ... | 71.0 | mixed deciduous/evergreen forest | 16.0 | 1.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vK | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 1406 | 8f61949b-d0cc-49c2-8b59-4e2938286da0 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | A3 | evergreenForest | 42.451400 | -72.250100 | ... | 71.0 | mixed deciduous/evergreen forest | 17.0 | 0.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vK | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 1407 | 36574bab-3725-44d4-b96c-3fc6dcea0765 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B3 | evergreenForest | 42.451400 | -72.250100 | ... | 71.0 | mixed deciduous/evergreen forest | 19.0 | 0.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vK | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 1408 | eb6dcb4a-cc6c-4ec1-9ee2-6932b7aefc54 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | A1 | evergreenForest | 42.451400 | -72.250100 | ... | 71.0 | deciduous forest | 19.0 | 2.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vK | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 1409 | 51ff3c20-397f-4c88-84e9-f34c2f52d6a8 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B2 | evergreenForest | 42.451400 | -72.250100 | ... | 71.0 | evergreen forest | 19.0 | 3.0 | Bird Conservancy of the Rockies | NEON.DOC.014041vK | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
1410 rows × 31 columns
brd_countdata
| uid | namedLocation | domainID | siteID | plotID | plotType | pointID | startDate | eventID | pointCountMinute | ... | vernacularName | observerDistance | detectionMethod | visualConfirmation | sexOrAge | clusterSize | clusterCode | identifiedBy | publicationDate | release | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4e22256f-5e86-4a2c-99be-dd1c7da7af28 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | C1 | 2015-06-14T09:23Z | BART_025.C1.2015-06-14 | 1 | ... | Black-capped Chickadee | 42.0 | singing | No | Male | 1.0 | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 1 | 93106c0d-06d8-4816-9892-15c99de03c91 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | C1 | 2015-06-14T09:23Z | BART_025.C1.2015-06-14 | 1 | ... | Red-eyed Vireo | 9.0 | singing | No | Male | 1.0 | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 2 | 5eb23904-9ae9-45bf-af27-a4fa1efd4e8a | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | C1 | 2015-06-14T09:23Z | BART_025.C1.2015-06-14 | 2 | ... | Black-and-white Warbler | 17.0 | singing | No | Male | 1.0 | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 3 | 99592c6c-4cf7-4de8-9502-b321e925684d | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | C1 | 2015-06-14T09:23Z | BART_025.C1.2015-06-14 | 2 | ... | Black-throated Green Warbler | 50.0 | singing | No | Male | 1.0 | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| 4 | 6c07d9fb-8813-452b-8182-3bc5e139d920 | BART_025.birdGrid.brd | D01 | BART | BART_025 | distributed | C1 | 2015-06-14T09:23Z | BART_025.C1.2015-06-14 | 1 | ... | Black-throated Green Warbler | 12.0 | singing | No | Male | 1.0 | NaN | JRUEB | 20211222T013942Z | RELEASE-2022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 15378 | cffdd5e4-f664-411b-9aea-e6265071332a | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B2 | 2022-06-12T13:31Z | HARV_021.B2.2022-06-12 | 3 | ... | Belted Kingfisher | 37.0 | calling | No | Unknown | 1.0 | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 15379 | 92b58b34-077f-420a-871d-116ac5b1c98a | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B2 | 2022-06-12T13:31Z | HARV_021.B2.2022-06-12 | 5 | ... | Common Yellowthroat | 8.0 | calling | Yes | Male | 1.0 | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 15380 | 06ccb684-da77-4cdf-a8f7-b0d9ac106847 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B2 | 2022-06-12T13:31Z | HARV_021.B2.2022-06-12 | 1 | ... | Ovenbird | 28.0 | singing | No | Unknown | 1.0 | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 15381 | 0254f165-0052-406e-b9ae-b76ef4109df1 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B2 | 2022-06-12T13:31Z | HARV_021.B2.2022-06-12 | 2 | ... | Veery | 50.0 | calling | No | Unknown | 1.0 | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
| 15382 | 432c797d-c4ea-4bfd-901c-5c2481b845c4 | HARV_021.birdGrid.brd | D01 | HARV | HARV_021 | distributed | B2 | 2022-06-12T13:31Z | HARV_021.B2.2022-06-12 | 4 | ... | Pine Warbler | 29.0 | singing | No | Unknown | 1.0 | NaN | KKLAP | 20221129T224415Z | PROVISIONAL |
15383 rows × 24 columns
And now let's do the same with the 30-minute data table for biological temperature.
IRBT30 = pandas.read_csv('/Users/Shared/NEON_temp-bio/stackedFiles/IRBT_30_minute.csv')
IRBT30
| domainID | siteID | horizontalPosition | verticalPosition | startDateTime | endDateTime | bioTempMean | bioTempMinimum | bioTempMaximum | bioTempVariance | bioTempNumPts | bioTempExpUncert | bioTempStdErMean | finalQF | publicationDate | release | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | D18 | BARR | 0 | 10 | 2021-09-01T00:00:00Z | 2021-09-01T00:30:00Z | 7.82 | 7.43 | 8.39 | 0.03 | 1800.0 | 0.60 | 0.00 | 0 | 20211219T025212Z | PROVISIONAL |
| 1 | D18 | BARR | 0 | 10 | 2021-09-01T00:30:00Z | 2021-09-01T01:00:00Z | 7.47 | 7.16 | 7.75 | 0.01 | 1800.0 | 0.60 | 0.00 | 0 | 20211219T025212Z | PROVISIONAL |
| 2 | D18 | BARR | 0 | 10 | 2021-09-01T01:00:00Z | 2021-09-01T01:30:00Z | 7.43 | 6.89 | 8.11 | 0.07 | 1800.0 | 0.60 | 0.01 | 0 | 20211219T025212Z | PROVISIONAL |
| 3 | D18 | BARR | 0 | 10 | 2021-09-01T01:30:00Z | 2021-09-01T02:00:00Z | 7.36 | 6.78 | 8.15 | 0.06 | 1800.0 | 0.60 | 0.01 | 0 | 20211219T025212Z | PROVISIONAL |
| 4 | D18 | BARR | 0 | 10 | 2021-09-01T02:00:00Z | 2021-09-01T02:30:00Z | 6.91 | 6.50 | 7.27 | 0.03 | 1800.0 | 0.60 | 0.00 | 0 | 20211219T025212Z | PROVISIONAL |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 13099 | D18 | BARR | 3 | 0 | 2021-11-30T21:30:00Z | 2021-11-30T22:00:00Z | -14.62 | -14.78 | -14.46 | 0.00 | 1800.0 | 0.57 | 0.00 | 0 | 20211206T221914Z | PROVISIONAL |
| 13100 | D18 | BARR | 3 | 0 | 2021-11-30T22:00:00Z | 2021-11-30T22:30:00Z | -14.59 | -14.72 | -14.50 | 0.00 | 1800.0 | 0.57 | 0.00 | 0 | 20211206T221914Z | PROVISIONAL |
| 13101 | D18 | BARR | 3 | 0 | 2021-11-30T22:30:00Z | 2021-11-30T23:00:00Z | -14.56 | -14.65 | -14.45 | 0.00 | 1800.0 | 0.57 | 0.00 | 0 | 20211206T221914Z | PROVISIONAL |
| 13102 | D18 | BARR | 3 | 0 | 2021-11-30T23:00:00Z | 2021-11-30T23:30:00Z | -14.50 | -14.60 | -14.39 | 0.00 | 1800.0 | 0.57 | 0.00 | 0 | 20211206T221914Z | PROVISIONAL |
| 13103 | D18 | BARR | 3 | 0 | 2021-11-30T23:30:00Z | 2021-12-01T00:00:00Z | -14.45 | -14.57 | -14.32 | 0.00 | 1800.0 | 0.57 | 0.00 | 0 | 20211206T221914Z | PROVISIONAL |
13104 rows × 16 columns
Download remote sensing files: byFileAOP()
The function byFileAOP() uses the NEON API
to programmatically download data files for remote sensing (AOP) data
products. These files cannot be stacked by stackByTable() because they
are not tabular data. The function simply creates a folder in your working
directory and writes the files there. It preserves the folder structure
for the subproducts.
The inputs to byFileAOP() are a data product ID, a site, a year,
a filepath to save to, and an indicator to check the size of the
download before proceeding, or not. As above, set check_size="FALSE"
when working in Python. Be especially cautious about download size
when downloading AOP data, since the files are very large.
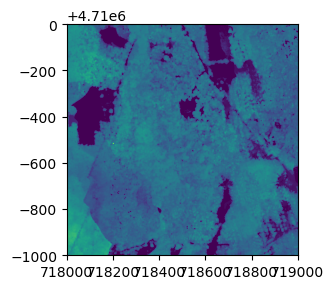
Here, we'll download Ecosystem structure (Canopy Height Model) data from Hopbrook (HOPB) in 2017.
neonUtilities.byFileAOP(dpID='DP3.30015.001', site='HOPB',
year='2017', check_size='FALSE',
savepath='/Users/Shared');
Downloading files totaling approximately 147.930656 MB
Downloading 217 files
|======================================================================| 100%
Successfully downloaded 217 files to /Users/Shared/DP3.30015.001
Let's read one tile of data into Python and view it. We'll use the
rasterio and matplotlib modules here, but as with tabular data,
there are other options available.
import rasterio
CHMtile = rasterio.open('/Users/Shared/DP3.30015.001/neon-aop-products/2017/FullSite/D01/2017_HOPB_2/L3/DiscreteLidar/CanopyHeightModelGtif/NEON_D01_HOPB_DP3_718000_4709000_CHM.tif')
import matplotlib.pyplot as plt
from rasterio.plot import show
fig, ax = plt.subplots(figsize = (8,3))
show(CHMtile)
<AxesSubplot:>
fig